Arquivos duplicados? fdupes neles!
Veremos aqui como recuperar espaço em disco utilizando a ferramenta fdupes, que trata da remoção dos arquivos duplicados.
[ Hits: 52.503 ]
Por: edps em 13/01/2012 | Blog: https://edpsblog.wordpress.com/

Utilização
fdupes -rnA -m TMP/
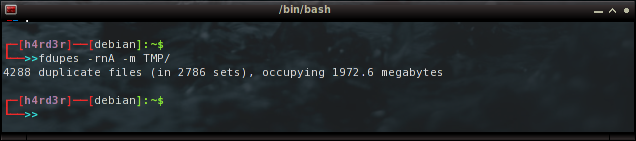
Que retorna com o resultado de 4288 arquivos duplicados, isso de um total de 9969:
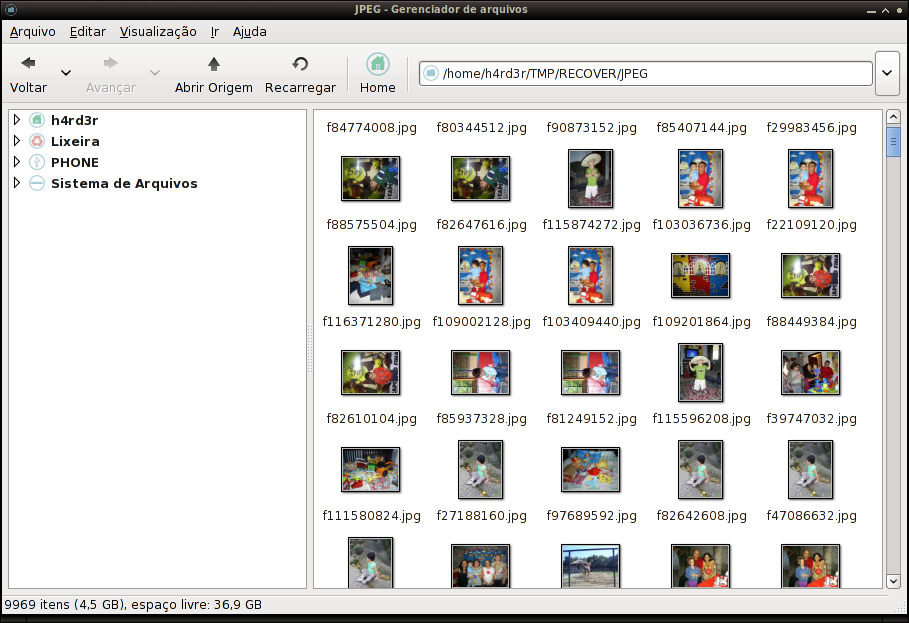
Agora sim, vamos começar a brincadeira...
Na imagem abaixo, ao invés de remover os arquivos duplicados, poderíamos apenas criar 'hardlinks' para os mesmos relacionando-os à 1ª imagem (ou arquivo) encontrado:
fdupes -frnA -NL TMP/
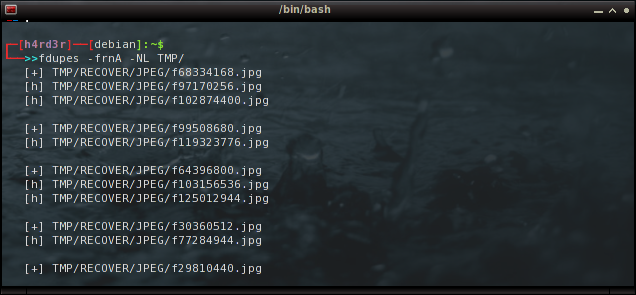
* Vejam que adicionei a opção (f) de omitir o 1º arquivo encontrado e substituí a opção (m) pelas opções (N) de 'no-prompt'|ou|sem confirmação e (L) de criar hardlink.
** A grande desvantagem deste modelo é que não haverá liberação de espaço em disco já que não ocorrerá a exclusão dos arquivos duplicados.
Delete os arquivos duplicados!
Na imagem a seguir vejam que repito o mesmo comando na pasta "TMP" e o 'fdupes' nada me retorna.
fdupes -frnA -NL TMP/
Na mesma imagem, substituo a opção (L) de criar 'hardlink', pela opção (d), de deletar arquivos duplicados. Vejam que o novo comando é executado na pasta "TMP2", que é na verdade uma pasta de backup. Ou você acham que vou mandar excluir os arquivos que acabei de recuperar sem fazer uma cópia de segurança? rsrsrs
fdupes -frnA -Nd TMP2/
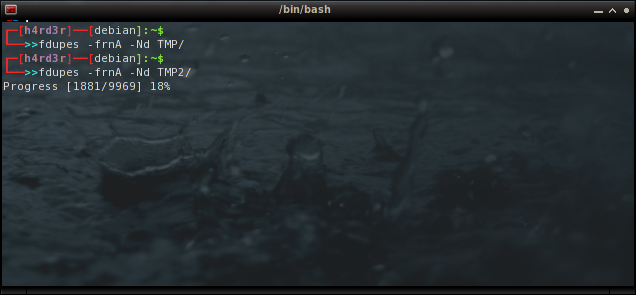
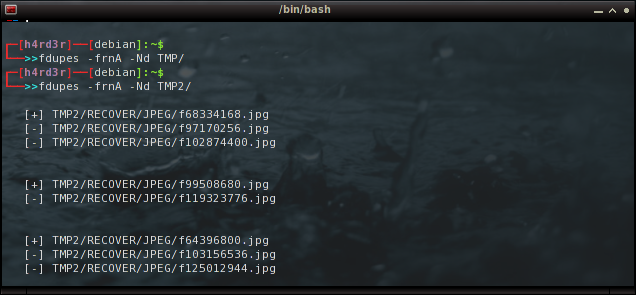
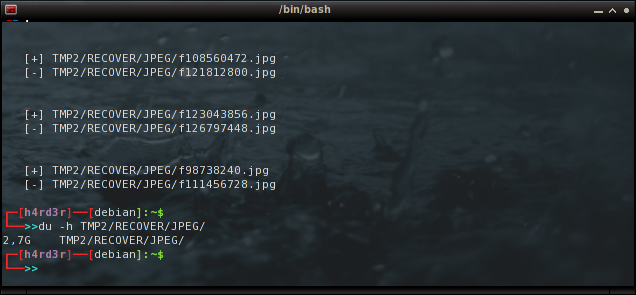
E com o comando abaixo, verifico que agora a pasta ocupa somente 2.7 GB (antes eram 4.5GB). Nada mal!
du -h TMP2/RECOVER/JPEG/
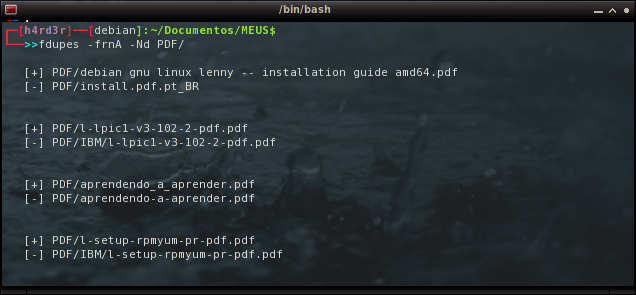
Em face à eficiência do programa, resolvo começar uma limpeza em meus arquivos, começando pela pasta de "PDFs":
cd Documentos/MEUS
$ fdupes -frnA -Nd PDF/
E na pasta de backup das 'configs' e pacotes do meu Debian, vou sem a opção (N) de 'no-prompt':
cd /media/backups
$ fdupes -frnA -d DEBIAN/
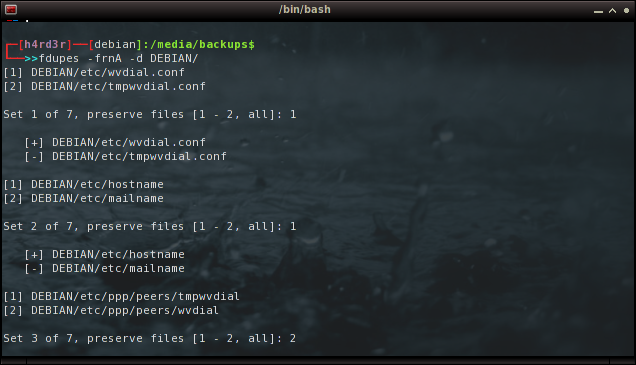
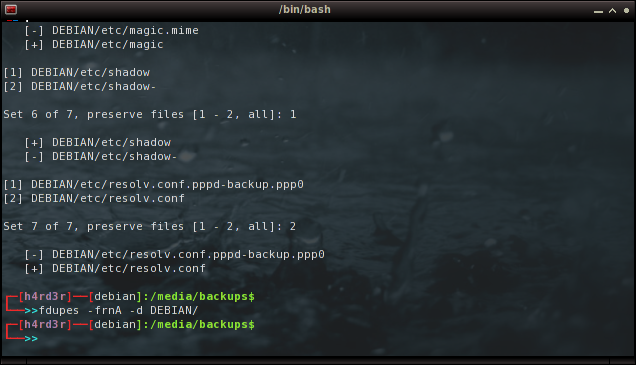
Obviamente, a cada arquivo duplicado encontrado devemos responder qual manter, se apenas um ou todos, ou simplesmente cancelar teclando 'Ctrl+C', simples assim!
Tivesse esta ideia a algum tempo atrás, ao menos não teria deletado deliberadamente os artigos e dicas que costumava guardar. Sim... é isso mesmo! Em plena era da Internet, essa é uma mania que eu tenho, guardar artigos para consulta posterior. Na verdade eram mais de 2 GBs de arquivos, sejam em ".html", ".pdf", ".mht", entre outros.
Com o 'fdupes', certamente eu teria reduzido o espaço em disco ocupado pelos famosos arquivos duplicados!
Um abraço e até o próximo!
Também publicado em meu Blog:
2. Utilização
ARM, utilização de snapshot de pacotes no Arch Linux
MATE Desktop 1.16.0 [GTK3] no Slackware
Siduction - Nova distro baseada no Debian SID
Configurando o modem ZTE MF626 com Vivo3G no Debian
Sabayon CoreCDX FluxBox 5.3, excelente!
Entendendo as permissões de arquivos (chmod)
Owncloud com autenticação no Active Directory
Aprendendo NFS - Network File System
RAID, tudo que você precisa saber
GlusterFS - Um Sistema de Arquivos Distribuídos (parte 2)
Show de bola edps ! Excelente artigo.
Ótima ferramenta, não conhecia esta.
Valeu cara.
Abraço.
Valeu pessoal,
obrigado pelos comentários.
Olá EDPs,
Vou testar sua dica, muito obrigado por repartilhar conosco!
Boa EDPS,
Com tua dica, limpei minha área de trabalho, tá sem arquivos duplicados!
Muito Obrigado ;)
Parece que advinha oq to procurando
Vou testar agora!
E outra coisa, como deixa o terminal assim? *-*
Obrigado pelos comentários;
@mbrainiac, @andretyn e @crf-rafa.
A todos os que lerem recomendo que antes de executar qualquer tarefa, SEMPRE façam backups do que irá ser alterado.
@@crf-rafa, é uma alteração no arquivo ~/.bashrc :
http://www.vivaolinux.com.br/artigo/O-bashrc-de-meu-Debian/
O bug do PcManFM ao mover arquivos foi resolvido:
http://img196.imageshack.us/img196/3244/pcmanfmlog.png
* verifiquei movendo uma pasta com muitos arquivos e cancelei a operação para ver o que ocorreria, não tive problemas.
Muito bom este programa.
Com fdupes -frAn -Nd /pasta resolvo tudo!
Valeu pela dica.
edps tenho a seguinte dúvida se puder resolver:
Meu problema é que preciso buscar duplicados em 2 pastas que juntas passam de milhões de arquivos. Elas tem 2Tb de tamanho. Essas 2 pastas são arquivos que eu recuperei e claro existem duplicados com os que estou usando HOJE.
O fdupes funciona, já o testei, mas minha dificuldade está em DIZER a ele ONDE APAGAR!
Exemplo: Comparando a pasta 1 com a pasta 2
1) Meus Arquivos na pasta 1 (Não podem ser apagados sob hipótese alguma)
2) Os arquivos que estiverem duplicados na pasta 2 DEVEM ser apagados.
PROBLEMA: Não encontrei um critério que permita colocar SEMPRE na 1 opção meus arquivos da pasta 1
Acontece do fdupes ora colocar a pasta 1 primeiro e ora colocar a pasta 2 primeiro
Isso me impede de usar exclusão automática. E não posso usar manual porque eu levaria anos fazendo isso!
Pode ajudar?
Olá,
Existe maneira de aplicar o fdupes apenas sobre ficheiros do tipo PDF?
Isto de apagar duplicados é muito bom mas tem um problema. Imagina que tens arquivos de programas de C ou de outro qualquer. Por norma são programas que tu tens o executável numa pasta e nessa mesma pasta tens vários arquivos que precisas para executar o programa com sucesso. Acontece que se tiveres várias pastas dessas, vários programas de um determinado software, existem muitos ficheiros duplicados. O ficheiro xpto.cgf existe em cada uma das pastas que tens correspondente ao programa fazerCódigo da microsoft, imaginem. Se vai aplicar o fdupes ele vai apagar todos os xpto.cgf que encontrar e manter apenas um. Quando fores abrir o programa este já não vai dar, pois falta o tal ficheiro. Não sei se consegui explicar bem!
@perfection
Não queres apagar os ficheiros da pasta 1 porque depois corres o risco de ter o ficheiro mas na pasta 2. E isso não pode acontecer, pois não queres mexer na pasta1, é isso?
Obrigado
Olá!
Muito boa a dica!
Gostaria de saber se essa opção -L ainda existe? Pois na minha instalação do fduples não tem como chamar ela.
Obrigado!
[12] Comentário enviado por ramon.rdm em 08/01/2019 - 11:02h
Olá!
Muito boa a dica!
Gostaria de saber se essa opção -L ainda existe? Pois na minha instalação do fduples não tem como chamar ela.
Obrigado!
Rapaz eu não estou usando o programa atualmente, mas acho que tem opções que não mais existem, não lembro se é a -A, ou outra, na dúvida veja a manpage:
$ man fdupes
Se te interessar veja também isso:
https://edpsblog.wordpress.com/2018/11/02/how-to-remocao-de-arquivos-duplicados-com-rdfind/
Patrocínio

Destaques
Artigos
File Browser: Crie sua Nuvem Pessoal Privada
A produção de áudio e vídeo no Linux e as distribuições dedicadas a esse fim
Criptografando sua Home com Gocryptfs para tristeza do meliante
A Involução do Linux e as Lambanças Desnecessárias desde o seu Lançamento
O Journal no Linux para a guarda e consulta de logs do sistema
Dicas
Assistindo IPTV no Linux com Fred TV e Lista Free TV
Impressora Tomate MDK-007 no Ubuntu (ou qualquer distro Linux)
Acelerando a compilação de pacotes no Arch Linux (AUR) usando todos os núcleos do processador
Tópicos
VoidBR - Void Linux adaptado ao Brasil. (2)
Teclado sem conseguir usar o acento crase (2)
Warsaw no Ubuntu/Kubuntu 26.04, alguiém conseguiu? [RESOLVIDO] (2)
Continuando meus tópicos anteriores (13)
As Assinaturas Perderam o Negrito e o Itálico? [RESOLVIDO] (1)
Top 10 do mês
-

Xerxes
1° lugar - 157.149 pts -

Fábio Berbert de Paula
2° lugar - 82.690 pts -

Alberto Federman Neto.
3° lugar - 46.213 pts -

Buckminster
4° lugar - 42.031 pts -

Alessandro de Oliveira Faria (A.K.A. CABELO)
5° lugar - 39.623 pts -

edps
6° lugar - 34.753 pts -

Mauricio Ferrari (LinuxProativo)
7° lugar - 25.917 pts -

Sidnei Serra
8° lugar - 25.057 pts -

Andre (pinduvoz)
9° lugar - 24.083 pts -

Daniel Lara Souza
10° lugar - 23.867 pts
Scripts
A maior comunidade GNU/Linux da América Latina! Artigos, dicas, tutoriais, fórum, scripts e muito mais. Ideal para quem busca auto-ajuda.
Site hospedado por: