Por quê a locale.h não está funcionando no Windows, mas está funcionando no Linux ?
1. Por quê a locale.h não está funcionando no Windows, mas está funcionando no Linux ?

Jluckmay
(usa Ubuntu)
Enviado em 09/07/2020 - 23:18h
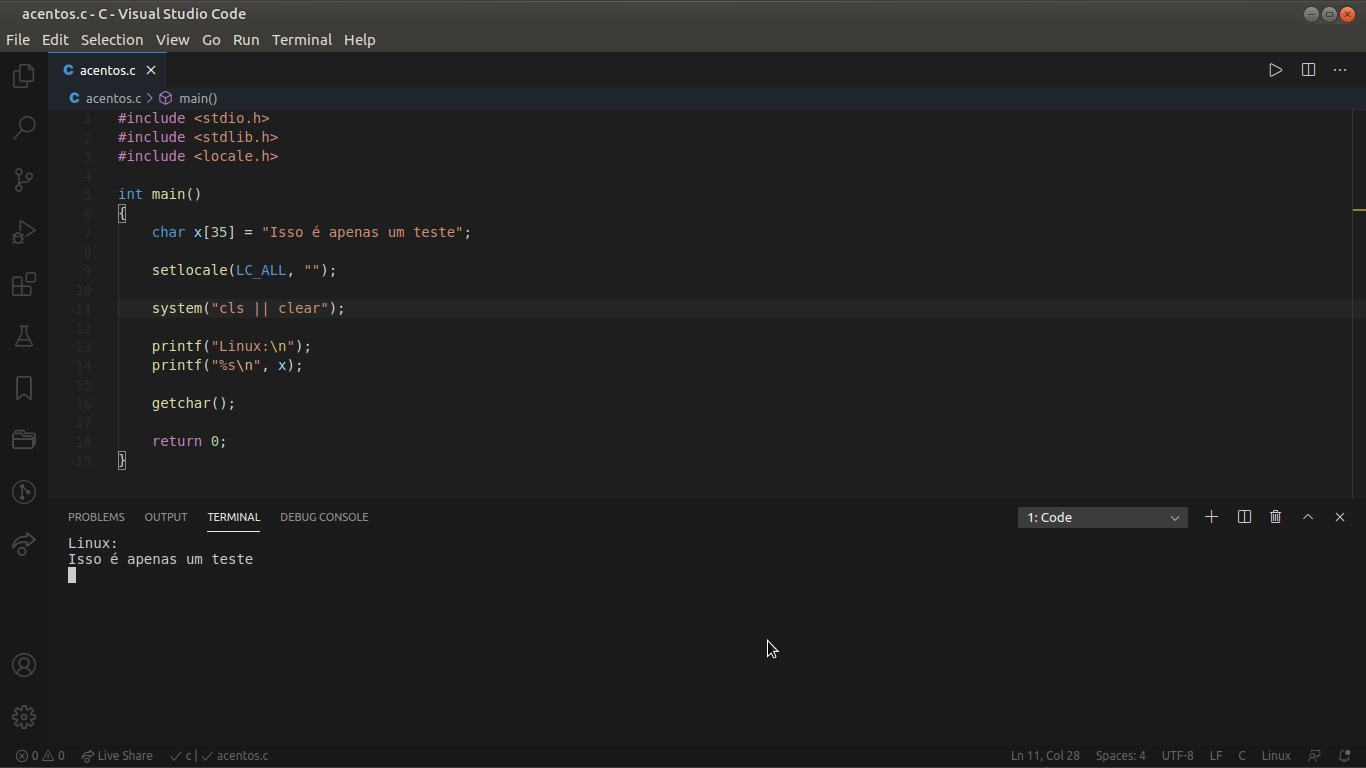
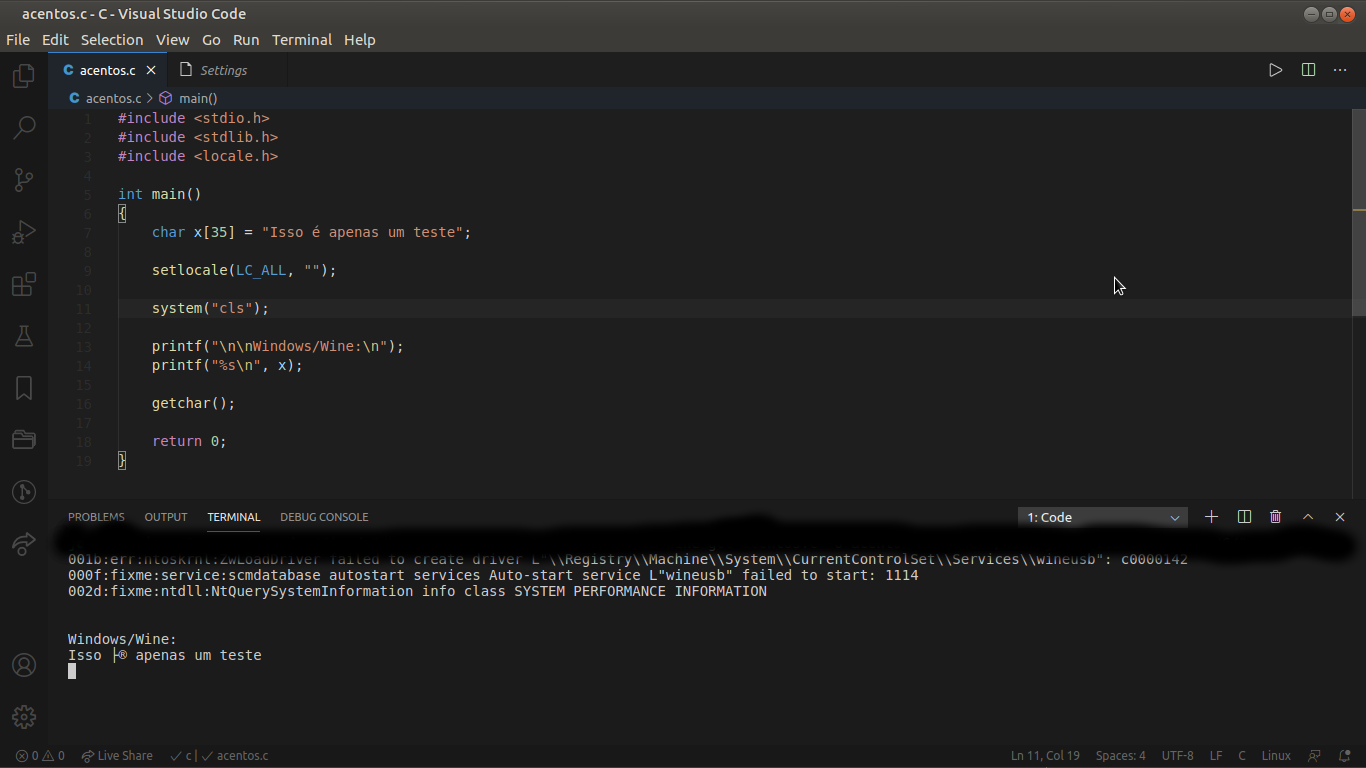
Gente, desde quando comecei a estudar C queria imprimir palavras com acento, mas não dava. Então procurei por uma biblioteca que me possibilitasse fazer isso, encontrei uma única biblioteca para tal tarefa: a locale.h. Bem, até ai nada errado, porém quando eu fiz a compilação cruzada para gerar um executável para Windows e o testei com o Wine os acentos apareceram bugados e um amigo meu que programa no Windows está com esse mesmo problema, ele não consegue utilizar a função setlocale dessa biblioteca para fazer os caracteres especiais serem impressos no terminal.Mas por que no Windows não funciona se no Linux vai? Há como fazer funcionar no Windows?
Busquei respostas para tais perguntas e em todos os cantos diz que funciona no Windows sim e que talvez tivesse que passar outros parâmetros. Passei tais parâmetros, mas não obtive sucesso em fazer a impressão de um acento se quer pelo Wine. Alguém sabe como resolver isso ou o porquê de funcionar em um mas não no outro?
Abaixo deixei prints de um código simples com a biblioteca rodando no Linux e no Windows.
Patrocínio

Destaques
Artigos
File Browser: Crie sua Nuvem Pessoal Privada
A produção de áudio e vídeo no Linux e as distribuições dedicadas a esse fim
Criptografando sua Home com Gocryptfs para tristeza do meliante
A Involução do Linux e as Lambanças Desnecessárias desde o seu Lançamento
O Journal no Linux para a guarda e consulta de logs do sistema
Dicas
Gerenciamento de Vídeo Híbrido (Intel/NVIDIA) via nvidia-prime no Ubuntu e derivados
Assistindo IPTV no Linux com Fred TV e Lista Free TV
Impressora Tomate MDK-007 no Ubuntu (ou qualquer distro Linux)
Acelerando a compilação de pacotes no Arch Linux (AUR) usando todos os núcleos do processador
Tópicos
Top 10 do mês
-

Xerxes
1° lugar - 159.954 pts -

Fábio Berbert de Paula
2° lugar - 81.716 pts -

Alberto Federman Neto.
3° lugar - 45.636 pts -

Buckminster
4° lugar - 40.157 pts -

Alessandro de Oliveira Faria (A.K.A. CABELO)
5° lugar - 39.883 pts -

edps
6° lugar - 34.671 pts -

Mauricio Ferrari (LinuxProativo)
7° lugar - 25.836 pts -

Sidnei Serra
8° lugar - 25.407 pts -

Andre (pinduvoz)
9° lugar - 24.612 pts -

Juliao Junior
10° lugar - 23.835 pts
Scripts
A maior comunidade GNU/Linux da América Latina! Artigos, dicas, tutoriais, fórum, scripts e muito mais. Ideal para quem busca auto-ajuda.
Site hospedado por: