Tutorial Kettle
O Kettle é uma ferramenta para integração de dados, responsável pelo processo de Extração, Transformação e Carga (ETL). Ferramentas ETL são utilizadas mais frequentemente em projetos de data warehouse, mas também podem ser utilizadas para outros propósitos, tais como migração de dados entre aplicações, exportação de banco para arquivos, limpeza de dados e na integração de aplicações.
[ Hits: 71.920 ]
Por: Giovanni Won Dias B. Victorette em 08/01/2010

Download e instalação
Dependendo da plataforma de trabalho, deve-se selecionar o pacote adequado e descompactar o mesmo. Neste tutorial iremos tratar apenas para os sistemas operacionais Windows e Linux. Caso o OS seja Linux basta abrir o local onde foi descompactado o kettle e executar spoon.sh e no caso do Windows spoon.bat Isso tudo tomando os devidos cuidados com permissões de execução e escrita.
Configurando um repositório
A figura 1 mostra a primeira tela apresentada na execução do Kettle. Nela existem duas opções: ou se configura um repositório onde ficarão armazenadas as Transformações e Jobs ou utiliza a ferramenta (No Repository) tendo que armazenar as Transformações e Jobs na máquina local.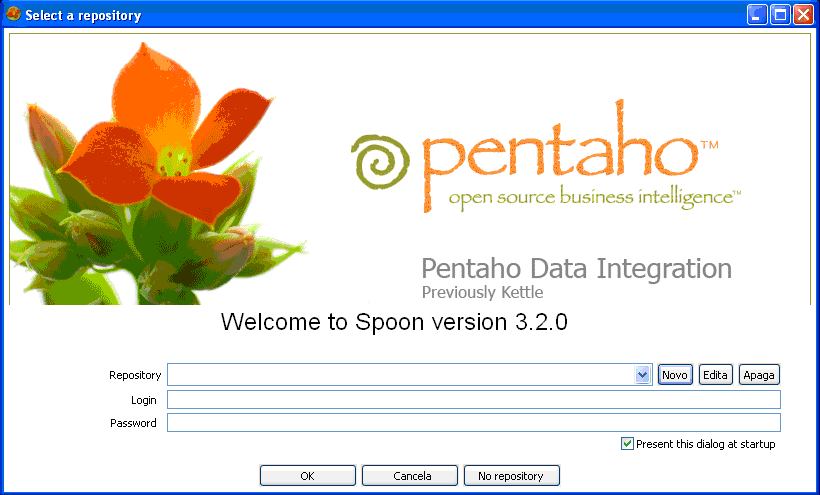
Figura 1 - Tela inicial
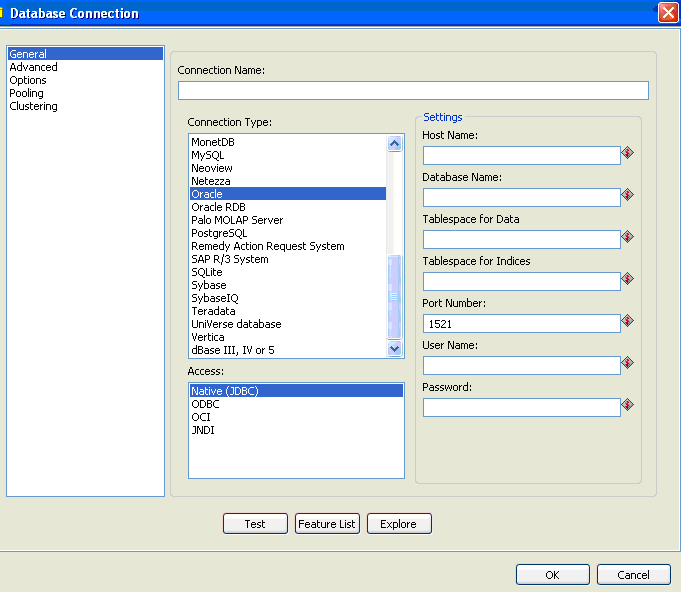
Figura 2 - Conexão com banco
Configurando conexão com banco
Na tela inicial do Kettle pode-se clicar em New > Database Connection (figura 3). Assim o sistema irá apresentar a tela da figura 2 onde se devem preencher os dados de acordo com o que for solicitado.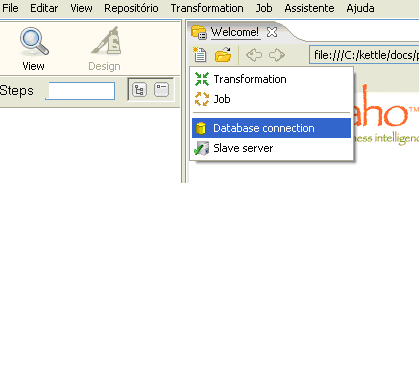
Figura 3 - Nova conexão
2. Download e instalação
3. Montando uma transformação
4. Utilizando variáveis e tratando strings
5. Utilizando Java Script e Database Lookup
6. Extração a partir de XML e XLS, montando um Job e utilizando serviços de FTP/e-mail
Montando um roteador com o floppyFW
BrOffice.org BASE: Criando banco de dados em 5 minutos
Paginação de resultados com a classe ADODB
Olá,
Gostaria de parabenizá-lo pelo artigo. Parece ser uma ferramenta interessante, dado que para BI, conheço somente ferramentas pagas, não caras, mas pagas. Mas, como comentário, ficou faltando somente esclarecer um pouco mais, dado que é uma ferramenta de ETL, sobre as suas bases : Granularidade, Dimensões, Fatos... Bom, mas ficou muito bom.
Parabéns
Abraços
Obrigado pelo comentário,
Sobre data warehouse apenas comentei no texto, se tiver que escrever algo vai render outro artigo, mas já existe muito material publicado sobre o tema na internet. O foco aqui é mesmo a ferramenta e os primeiros passos com a mesma.
Abraços
Olá Giovanni,
Parabéns pelo trabalho apesar de não ter lido todo o artigo vejo que vc se esforçou para fazer um bom e apresentável artigo.
Segue meu site, www.ademargomes.com, onde você pode encontrar bastante material sobre Kettle e outras coisas.
Me senti a vontade de colocar aqui meu site pois escrevi um artigo de Kettle muito próximo do seu, mas esse foi pro site no ano passado, por tanto não tem plagio :)
Sorte e Sucesso,
AdeamrGomes
P.S. Link do artigo: http://www.ademargomes.com/index.php/artigos/56-turialkettle.html
Estou tentando criar alguns "mapas" com o Kettle e me deparei com uma barreira: como utilizar os dados de um Input "pai" para retornar valores de um Input "filho" ?
Explico: digamos que tenho que montar um arquivo de Pedidos no seguinte formato:
CAPA: NRO_PEDIDO | DATA_PEDIDO | VALOR
ITENS:NRO_PEDIDO | NRO_PRODUTO|QTD|PRECO
Exemplo:
101|2010-02-26|100,00
101|123|1,00|40,00
101|321|2,00|30,00
102|2010-02-26|20,00
102|456|2,00|10,00
Penso que para construir algo parecido eu utilizaria um Input com uma query buscando as capas de pedidos, e o fluxo (ou hop) seguiria para outro Input, desta vez buscando os itens. Este é o ponto: como fazer o segundo Input receber um valor do primeiro input?
Em resumo:
Input_nro_1: select nro_pedido, data_pedido, valor from PEDIDO;
Input_nro_2: select nro_produto, qtd, preco from ITEM_PEDIDO where nro_pedido = Input_nro_1.Nro_pedido
Deu pra entender?
valeu!
Henrique,
Vamos ver se entendi, existem formas de se fazer o que precisa:
1) As tabelas estão na mesma base? se estão pode montar a consulta em um único "input"
ficaria:
SELECT c.nro_pedido, c.data_pedido, c.valor
FROM CAPA c
INNER JOIN ITENS i
ON c.nro_pedido = i.nro_pedido
2) Se estão em bases distintas, utiliza-se o passo de JOIN que existe no kettle para realizar esta junção entre os dois inputs;
Valeu!
Opa, não tinha visto que tinha retornado ao meu comentário...
Bem, vamos lá... vc quase entendeu.
É o caso 1, estão na mesma base. Mas eu gostaria de tratar em inputs distintos, ou seja, capa em um input e item em outro input. Entretanto, o input2, ou seja, dos itens, iria ser aberto para cada capa.
Pq isto? Pq eu quero gravar a capa do pedido no destino e depois o item, mas eu preciso garantir a integridade dos dados, ou seja, eu tenho que gravar a capa antes de gravar o item, e para isto acredito que tenho que abrir o Input do item apenas após realizar o output da capa.
Um diagrama de exemplo seria assim:
|CAPA|--->---|OUTPUT|--->---|ITEM|--->---|OUTPUT|
Deu para entender?
Ou o correto neste caso seria um Transformation para Capa e outro Transformation para Item?
valeu!!
Giovanni, parabéns pela iniciativa. Estou dando meus primeiros passos rumo a BI. Participei de um treinamento em Brasília/DF com Caio Moreno (o professor coruja - http://blog.professorcoruja.com) e estou finalizando "Inteligência Competitiva" pela FGV.
Passou por um problemão por mais de 30 dias: conectar ao DB Progress via JDBC. Consegui, Ufa! Criei http://inpentaho.blogspot.com para deixar a solução registrada.
Não pare de postar sobre o KETTLE.
Jesus bless.
Patrocínio

Destaques
Artigos
File Browser: Crie sua Nuvem Pessoal Privada
A produção de áudio e vídeo no Linux e as distribuições dedicadas a esse fim
Criptografando sua Home com Gocryptfs para tristeza do meliante
A Involução do Linux e as Lambanças Desnecessárias desde o seu Lançamento
O Journal no Linux para a guarda e consulta de logs do sistema
Dicas
Acelerando a compilação de pacotes no Arch Linux (AUR) usando todos os núcleos do processador
Ocultando asteriscos ao digitar senha no Ubuntu
Tópicos
Continuando meus tópicos anteriores (13)
As Assinaturas Perderam o Negrito e o Itálico? [RESOLVIDO] (1)
Top 10 do mês
-

Xerxes
1° lugar - 158.687 pts -

Fábio Berbert de Paula
2° lugar - 82.925 pts -

Alberto Federman Neto.
3° lugar - 46.424 pts -

Buckminster
4° lugar - 43.250 pts -

Alessandro de Oliveira Faria (A.K.A. CABELO)
5° lugar - 39.459 pts -

edps
6° lugar - 34.815 pts -

Sidnei Serra
7° lugar - 26.118 pts -

Mauricio Ferrari (LinuxProativo)
8° lugar - 26.158 pts -

Daniel Lara Souza
9° lugar - 24.153 pts -

Andre (pinduvoz)
10° lugar - 24.066 pts
Scripts
A maior comunidade GNU/Linux da América Latina! Artigos, dicas, tutoriais, fórum, scripts e muito mais. Ideal para quem busca auto-ajuda.
Site hospedado por: