Entendendo os codecs, os containers formats e por que o Ogg é tão bom
Este artigo explica o que são e como funcionam os codecs, os formatos recipientes (conhecidos também como container formats) e os ótimos recursos do Ogg. Tudo com ótimos exemplos e ilustrações.
[ Hits: 32.532 ]
Por: Vinícius dos Santos Oliveira em 18/07/2009 | Blog: https://vinipsmaker.github.io/
Os codecs e o Container Format - a explicação
Quando você vê uma imagem no computador, é uma ilusão gerada pelo cérebro, que não percebe as imperfeições escondidas na tela do monitor. O monitor mostra um monte de pontos quadrados, cada um com uma cor diferente, mas os pontos são tão pequenos que o cérebro não percebe a ilusão por completo (você provavelmente tem dois olhos e graças a isso tem a noção de profundidade). A ilusão de movimento é gerada pela sequência de imagens, que têm um intervalo de tempo entre uma imagem e outra tão curto, que o cérebro não percebe a ilusão de movimento (mas dessa vez não percebe nenhuma parte da ilusão).
Certo, agora que você já sabe disso, precisa (caso ainda não tenha) de outra explicação. O computador armazena as informações agrupando bits. Os bits são os algarismos. Algumas pessoas não sabem a diferença, na matemática, entre algarismo e número mesmo depois de terminar a universidade (às vezes de matemática), então vou explicar isso também.
2520 é um número, com quatro algarismos. 2 e 64 são dois números, sendo que 2 é formado por um algarismo e 64 é formado por dois algarismos. Os bits também são algarismo, mas são algarismos de números do sistema numérico binário, isso significa que em vez de contar "1, 2, 3, 4, 5, 6, 7, ..." você conta (no sistema numérico binário) "1, 10 , 11, 100, 101, 110, 111, 1000, ...". Sendo assim o bit pode ser 1 ou 0.
Os bytes são o conjunto de 8 bits. Dois bytes formam um valor que, consultando uma tabela, simboliza uma letra. Quanto mais bits houver, mais espaço o arquivo vai ocupar no HD (ou outro dispositivo de armazenamento). Agora que você já entendeu o básico sobre como o computador armazena os arquivos, prossigamos com a explicação.
Imagine o gráfico de uma função. Agora imagine que um arquivo armazena cada ponto do gráfico. Esse arquivo é grande, mas o computador não precisa calcular onde estão os pontos da equação. Agora imagine outro arquivo que representa a mesma função, porém, em vez de armazenar cada ponto da equação, ele armazena a equação (ou equações, dependendo da complexidade do que você imaginou) do gráfico. O segundo arquivo é muito menor, porém pode demorar um pouco mais para abrir, pois a máquina irá precisar calcular as retas (ou círculos) da equação. Você acaba de entender os CODECS, mas além destas técnicas, há outras técnicas para comprimir arquivos.
A palavra codec vem de (en)COder e DECoder, que significam, respectivamente, codificador e decodificador. Eles são usados para codificar e comprimir vídeos e áudio digitais e decodificá-los também. Há três principais tipos de codecs:
- Sem compressão: Nestes codecs as informações são armazenadas exatamente como são recebidas, então os arquivos gerados são bem grandes, pois não há compressão de informações. Algumas vantagens de codecs que não usam compressão de dados é que eles exigem pouco poder de processamento e são ótimos para edição. A principal desvantagem é que os arquivos gerados por estes codecs ocupam muito espaço.
- Compressão sem perdas: Com estes codecs é diferente. As informações são comprimidas (eliminando redundâncias, usando quantização e outras técnicas) e os arquivos gerados são bem menores do que os originais. Uma grande vantagem deles é que nenhuma informação é perdida, então quando você quiser usar outro codec a qualidade será preservada, pois a informação processada pelo decodificador é a mesma recebida pelo codificador.
- Compressão com perdas: Neste tipo de codec parte das informações recebidas pelo codificador são descartadas para diminuir o tamanho do arquivo. Então você talvez pense "Mentira! Outro dia alguém me enviou uma foto no formato JPEG (onde há perda de informações) e a foto está perfeita". Bons codificadores descartam informações que geralmente não são percebidas pelos sentidos humanos (em fotos JPEG, as cores descartadas, são aquelas que estão MUITO próximas e são MUITO parecidas). Estes são os codecs mais utilizados hoje, mas não são muito usados por aqueles (como eu) obcecados por qualidade. Os arquivos gerados por estes codecs são geralmente os menores e o poder de processamento requerido é quase sempre maior que os requeridos pelos codecs sem-compressão. Quando o codec é muito complexo, chega a necessitar mais poder de processamento que os codecs onde há compressão sem perdas.
Apesar de haver três tipos de codecs eles são geralmente agrupados em lossy (com perda de informações) e lossless (sem perda de informações). Agora vamos a explicação de formato recipiente.
Os codecs (principalmente os mais complexos) geram muitas informações e isso tudo fica agrupado nos arquivos, mas como separar estas informações estando elas todas no mesmo arquivo? O formato recipiente é um tipo de arquivo que armazena os bytes gerados pelos codecs e outras informações que são necessárias para decodificá-los (como resolução, taxa de frames por segundo, nome do vídeo/áudio/artista, taxa de bits por segundo, qual codec deve ser utilizado para decodificá-lo, entre outros). Eles funciona assim:
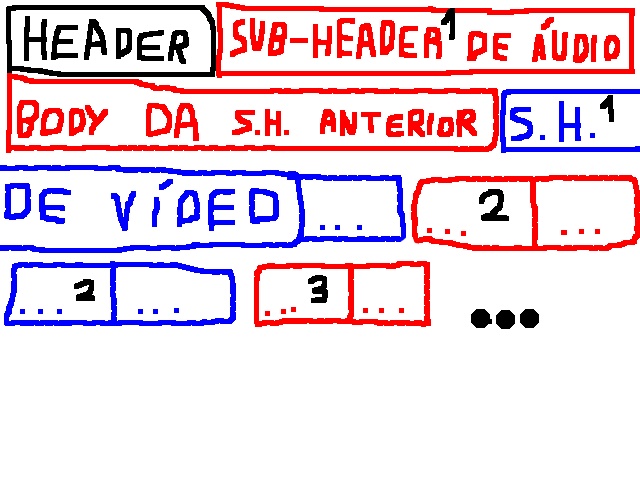
O arquivo é separado em várias partes. Os primeiros n bytes do arquivo formam a parte chamada de HEADER (que significa cabeça em inglês) e serve para identificar o arquivo. Nesta parte os primeiros y bytes podem identificar o tipo de arquivo recipiente, assim, mesmo que a extensão do arquivo esteja errada, o reprodutor multimídia ainda poderá ler o arquivo. Depois disso há bytes de tamanho fixos que informam por quantas partes o arquivo é formado e qual codec deve ser utilizado para decodificar cada parte.
As outras partes são formadas por um SUBHEADER, que identifica a parte e tem informações como "o tamanho da parte", "a resolução do vídeo (caso esta parte armazene um vídeo), entre outros e também por BODYs (que significa corpo em inglês), que são o conteúdo descrito pela HEADER e SUBHEADER. Mas há outros nomes para BODY como Ogg pages nos recipientes Ogg e chunk em alguns dos outros. Se algum HEADER (ou identificador) principal for danificado, o arquivo provavelmente não poderá ser decodificado (ou será decodificado erroneamente).
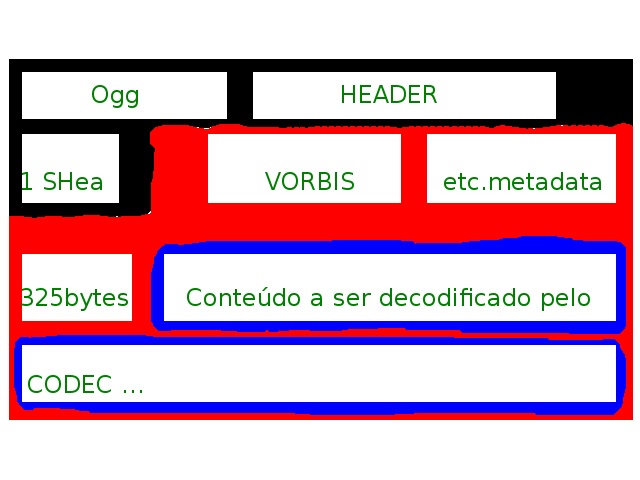
Há dois tipos principais de formatos recipientes e eles tem propósitos diferentes:
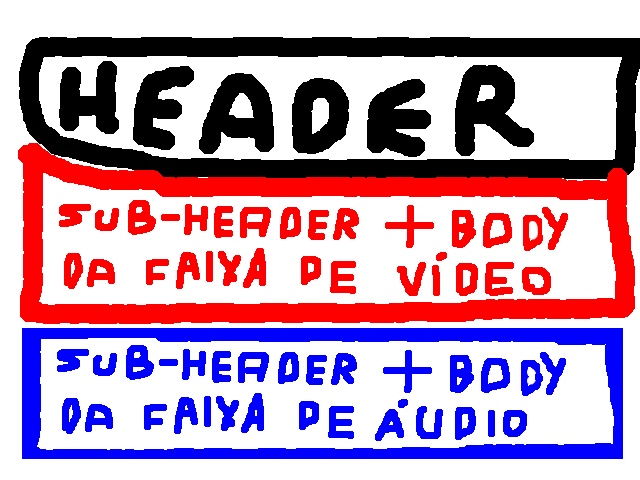
- Sem intervalo: Este é o tipo de codec onde o BODY não é cortado, ele ocupa um espaço contínuo. Este tipo de formato recipiente costuma ter poucas subheaders e, por consequência, ocupar um pouco menos de espaço em disco, além de serem menos complexos. Costumam ser utilizados para reprodução local e como formato de edição. Exemplo:
O problema com os formatos recipientes sem intervalo é com os vídeos que devem ser distribuídos na internet. Imagine se os vídeos armazenados no YouTube usassem um formato recipiente sem intervalos. O navegador começaria a carregar uma das faixas (áudio OU vídeo) e só passaria a exibir a faixa seguinte após carregar completamente esta faixa.
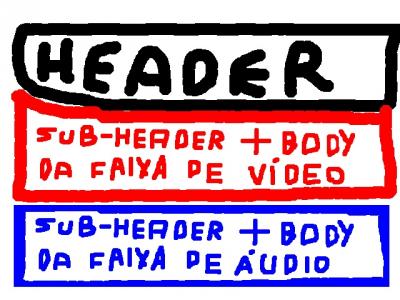
Então se a faixa que viesse primeiro fosse a de vídeo, você poderia assistir a faixa de vídeo (que, obviamente, não armazena som) e, após seu carregamento, escutar a faixa de áudio a medida que ela é carregada. Ou poderia esperar o carregamento da faixa de vídeo por completo e então assistir o vídeo (com o áudio) a medida que a faixa de áudio é carregada/baixada.
Há este problema para distribuição via internet e você só pode ter uma prévia do vídeo após baixar grande parte dele. Foi por isso que surgiram os formatos recipientes com intervalos.
- Com intervalo: Nestes formatos recipientes as faixas (de áudio, vídeo, legendas e outros) são cortadas em pedaços menores e entrelaçadas para que o arquivo possa ser distribuída pela internet amigavelmente, pois cada parte do arquivo contém o vídeo, o áudio e/ou outras faixas. O arquivo abaixo demonstra resumidamente isso:
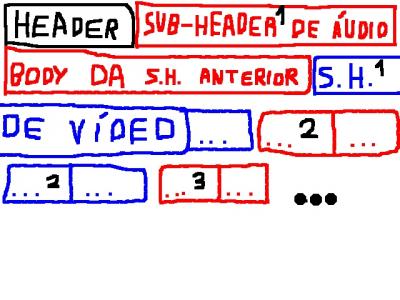
2. O Ogg
3. Conclusão
Tratamento de exceções na linguagem C
História da informática: Um pouco de datas e especificações
Aplicativos web em C++ usando o Tufão
Mupen64plus, o melhor emulador de Nintendo 64 disponível para GNU/Linux
Os Caminhos Para Certificação LPI1
Personalidades do mundo Open Source
Boa Noite !!!
Gostei muito das informações sobre o OGG, não sabia que ele tinha tantas qualidades.
Procurei salvar minhas músicas em ogg.
Jairus Lopes
Esqueci de informar sobre especificação e implementação. A especificação são as regras que podem ser usadas para codificar a faixa (vídeo, áudio ou qualquer outra coisa válida) e uma recomendação de como decodificá-la (alguém pode ter uma idéia interessante de como melhorar a qualidade usando um modo de decodificação diferente). E implementação é o resultado do trabalho do programador. Então, há a implementação oficial do vorbis e há uma outra implementação chamada aoTuV, cujo objetivo é aumentar a qualidade a baixas taxas de bits (bitrate), onde o tamanho do arquivo é menor. O vorbis é o melhor na especificação e sua implementação é muito proveitosa (a versão 1.3.0 vai implementar alguns aperfeiçoamentos do aoTuV, sendo que a versão atual já é bem interessante).
Outro link interessante que esqueci de colocar:
http://www.hydrogenaudio.org/forums/
Mais uma coisa, na segunda página eu informei que eu tinha conseguido aquelas informações através da XiphWiki, mas vamos considerar que metade daquela informação foi conseguida da página XiphWiki.
Por último, apesar de o Theora ainda não bater o MPEG-4, há o Dirac, codec com especificação incrível que se tivesse uma ótima implementação seria incrível para uso em qualquer situação. O Dirac não tem formato recipiente oficial, mas os seus desenvolvedores escreveram um material de como utilizá-lo no Ogg e em alguns outros já existente. Se a BBC (desenvolveu o Dirac) trabalhasse junto com o Monty seria muito mais proveitoso.
E Jairus, o Ogg sempre foi bom e eu escrevi este artigo (até agora o primeiro que não ficou com nota 10) porque eu quero compartilhar esse conhecimento com vocês. Pois muitas pessoas que usam linux continuam "baixando um mp3zinho da net" (mas não só os linuxers que deveriam usar padrões abertos). Vou depois fazer um artigo sobre o gstreamer e uma comparação entre ele e o sistema de codecs do windows.
EDIT:
Eu falei no artigo que sou absecado por qualidade e as imagens estão em jpeg (um formato que estraga a qualidade da imagem). Para aqueles que não gostaram dos arquivos:
http://www.vivaolinux.com.br/imagens/artigos/comunidade/conforogg01.png
http://www.vivaolinux.com.br/imagens/artigos/comunidade/conforogg02.png
http://www.vivaolinux.com.br/imagens/artigos/comunidade/conforogg03.png
Encontrei um link interessante A POUCO e quero compartilhá-lo:
https://wiki.mozilla.org/Accessibility/Video_a11y_Study08
Nessa página pode-ser concluir que a Mozilla está trabalhando no Ogg e que em breve ele poderá ter um formato padrão de legendas (espero eu que seja o OggKate, pois o OggKate, também desenvolvido pela Xiph.org, permite o uso de texto ou imagens para a produção de legendas, além de outras características interessantes que aumentam a acessibilidade), um sistema de capítulos dvd-like (estilo aqueles usados em dvds), entre outros.
Gostei muito das informações! Ótimo artigo.
Ei xerxeslins, resolveu o problema com o mupen?
Muito bom, não conhecia tanto sobre codecs.
Abraços
Eu já conhecia bastante os codecs (além de outras coisas), mas é difícil achar uma forma de explicá-los. Após esse tempo consegui descobrir uma forma de explicá-los, mas ainda acho que é possível encontrar um exemplo melhor para explicar a diferença entre especificação e implementação.
Eu sempre fui fã dos formatos de audio de código aberto especialmente o ogg e ficava encafifado ao ver que o bitrate não era fixo e depois fui compreender essas caracteristicas, sempre passo meus cds de áudio primeiro para FLAC como medida de segurança e depois para OGG para poder apreciar ultimamente tenho usado o OGG em 5 ou 6 canais para usufruir do áudio dos dvds e a qualidade do som é exelente costumo
usar o dvdtoogg,xcfa e outros métodos em linha de comando tudo feito com software livre se ainda não ouviu OGG 5.1 aí vai o endereço do meu diretório virtual contendo meus arquivos OGG 5.1
http://www.4shared.com/dir/16488817/c835f157/musicas_em_56_canais_ogg-vorbis.html
as faixas foram extraidas em ac3-normalizadas convertidas para FLAC e OGG(q8) depois para baixar o tamanho do arquivo reconverti
para a taxa de (192kbps abr) com o SoundKonverter e alguns cortes foram feitos no Audacity.
e dale TUX!!!!
e fica meu diretório virtual a disposição!! com muiti mais!!
http://www.4shared.com/u/pgkkmzrg/cd63dbd1/superlinux-mg.html
Já que o artigo teve uma boa recepção talvez eu faça uma continuação explicando as técnicas de compressão mais a fundo.
Valeu pela ajuda de comparação, superlinux-br, gostei do avatar com o logo da Xiph.org na sua pasta virtual no 4shared.
Muito bom artigo,
Parabéns.
Obs.:Gostei dos desenhos =), hsuahsa
[]'s
Parece que o artigo está crescendo e o que seria considerado por alguns como "mais um artigo que diz que codecs são usados para visualizar vídeos" está tornando-se surpreendente.
Lá na wikipedia em inglês tem um artigo chamado "Container format (digital)" e surpreendi-me quando vi que havia um artigo para o mesmo assunto na wikipedia versão português - é só entrar em http://en.wikipedia.org/wiki/Container_format_%28digital%29 e clicar em português. Mas surpreendi-me mais ainda quando vi a tradução que o "gênio" deu para "container format". A tradução que o "gênio" deu foi "Arquivos de vídeo". Depois de ver esta "brilhante tradução" eu não me surpreendi com o pouco conteúdo e a falta de explicação.
Alguém podia ir lá na wikipedia em português e criar um novo artigo com o nome "Formato recipiente" ou "Arquivo recipiente (digital)" e preencher algumas coisas baseadas no meu artigo? Depois digam qual o link comentando neste artigo e eu completo lá o que tiver faltando.
Criei a página na wikipedia, quem quiser ajudar:
http://pt.wikipedia.org/wiki/Arquivo_recipiente
Artigo com informação bastante útil e bem explicada.
Muito bom o artigo, vinipsmaker! Esclarecedor!
Ótimo artigo. Muito bom mesmo!
Pessoas como vc é que fazem diferença na sociedade. Obrigado por este trabalho; foi muito útil para mim, que sou leigo no assunto.
Patrocínio

Destaques
Artigos
A Fundação da Confiança Digital: A Importância Estratégica de uma PKI CA na Segurança de Dados
Como enviar dicas ou artigos para o Viva o Linux
Como Ativar a Aceleração por GPU (ROCm) no Ollama para AMD Navi 10 (RX 5700 XT / 5600) no Gentoo
Dicas
Configuração de IP fixo via nmcli e resolução de nomes via /etc/hosts no Gentoo
Removendo o bloqueio por erros de senha no Gentoo (systemd)
Papel de Parede Animado no KDE Plasma 6 (Com dicas para Gentoo)
Homebrew: o gerenciador de pacotes que faltava para o Linux!
Removendo a trava de versão do Project Brutality para GZDoom/UZDoom
Tópicos
Tentando fazer um "linux ricing" mas falhando miseravelmente... (0)
O que houve com slackware ??? (17)
Top 10 do mês
-

Xerxes
1° lugar - 124.825 pts -

Fábio Berbert de Paula
2° lugar - 51.471 pts -

Buckminster
3° lugar - 29.616 pts -

Sidnei Serra
4° lugar - 22.050 pts -

Alberto Federman Neto.
5° lugar - 18.087 pts -

Mauricio Ferrari (LinuxProativo)
6° lugar - 18.072 pts -

Daniel Lara Souza
7° lugar - 18.015 pts -

Alessandro de Oliveira Faria (A.K.A. CABELO)
8° lugar - 16.780 pts -

edps
9° lugar - 15.611 pts -

Diego Mendes Rodrigues
10° lugar - 13.661 pts
Scripts
A maior comunidade GNU/Linux da América Latina! Artigos, dicas, tutoriais, fórum, scripts e muito mais. Ideal para quem busca auto-ajuda.
Site hospedado por: