Conceito: Evitando acidentes com visão computacional
Neste documento, veremos conceitos computacionais sobre como utilizar recursos de visão computacional para detectar pedestres, ciclistas e animais. Câmeras com tal recurso adaptado em veículos poderiam evitar muitos acidentes. Sendo assim, deixo neste artigo todo o conceito computacional.
[ Hits: 19.343 ]
Por: Alessandro de Oliveira Faria (A.K.A. CABELO) em 04/08/2014 | Blog: http://assuntonerd.com.br

Introdução: Visão computacional

Visão computacional é uma divisão da computação que trabalha com o conceitos das máquinas que enxergam. Esta tecnologia é geralmente aplicada em robôs industriais, veículos autônomos, câmeras inteligentes, biometria e outros sistemas computacionais.
Trabalhos relacionados à visão computacional, têm ainda um longo caminho evolutivo, pois somente após o final da década de 70 que se iniciaram estudos aprofundados. Entretanto, a evolução do hardware e os seus respectivos recursos, vem ajudando muito ao progresso deste segmento.
A visão computacional é um problema mal posto, como também não existe uma formulação padrão para a resolução do mesmo, todos os métodos são baseados em aprendizagem e está cada vez mais comum no mercado de tecnologia.
O reconhecimento de padrões e a aprendizagem de máquina é um processo que consiste em determinar se uma imagem contém ou não um objeto. As principais lógicas de processamento estão classificadas geralmente em:
- Aquisição da imagem: geralmente a imagem é obtida através de um dispositivo de vídeo captura, câmeras digitais, celulares, smartphones e outros.
- Pré-processamento: geralmente, é necessário processar a imagem para garantir as condições mínimas. Por exemplo, redução de ruídos, balanceamento de brilho e contraste.
- Extração da características: características matemáticas em diversos níveis de dificuldades são extraídas. Como exemplo, o processo de detecção de borda, cantos, morfologia matemática e muitos outros.
- Segmentação: a seleção de regiões de interesse e/ou segmentação são incluídas nas áreas que contém o objeto.
- Processamento: um conjunto de dados é processado e verificado a satisfação e conformidades matemáticas.
O princípio computacional do título deste artigo, baseia-se com os devidos treinos computacionais (o qual não é o objetivo deste documento), podemos detectar animais, humanos, partes do corpo e objetos. Então, se identificados os itens mencionados, podemos estimar a ação do indivíduo e/ou animal e objeto.



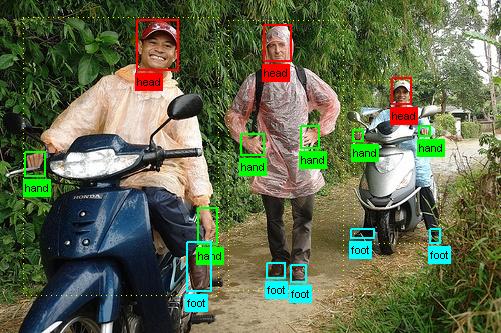
Após detectar as partes do corpo, calculamos os vetores para simplificar o trabalho do algoritmo de detecção de esqueleto. Sendo assim, facilmente identificamos, por exemplo, pedestres, ciclistas, cavalos e outros prováveis obstáculos possivelmente diante do veículo.

Com todas estas informações, as ações como pular, falar ao celular, tocar um instrumento, ler, cavalgar, correr, tirar foto, usar um computador e outros, tornaram-se uma tarefa tangível.
E a performance? Em 2011 utilizei a biblioteca OpenCV compilada com as chamadas do SDK NVIDIA. Ou seja, utilizei a GPU para obter o máximo desempenho na localização de padrões. No caso do vídeo demonstrativo a seguir uma face.
Atualmente, com a abertura do código Tegra para GNU/Linux, podemos em hardwares embarcados, utilizar todo o poder do hardware junto à biblioteca OpenCV e outros recursos/bibliotecas de visão computacional.
2. Mão na massa
Android NDK: Desmistificando o acesso a códigos nativos em C
Como instalar um display LCD em seu servidor Linux
openSUSE Linux no Windows 10 sem virtualização
A Inteligência Artificial que escreve programas
Como instalar Microsoft SQL SERVER no openSUSE Linux
Convertendo os Arquivos de Temas do Windows (.themepack) em Pacotes de Wallpapers Úteis para o Linux
Instalando Asterisk2Billing no SuSE 10.0
Introdução ao APLINUX.com.br Mail Server 2005
Como instalar o compilador Free Pascal
Cabelo, só uma curiosidade. Acredito que o proposto neste artigo é o mesmo princípio aplicado em alguns veículos da Volvo, que detectam obstáculos como os mencionados e executa frenagem no veículo sem intervenção humana, desde que o mesmo veículo esteja em uma velocidade de até 30km/h. Seria a mesma aplicação?
Grande abraço.
Levando em consideração tecnologia como tegra 3 ou superior e o processamento acima de 30 quadros por segundos (no video do artigo chegamos a mais de 100). Podemos gerar alertas sonoros como também tomar alguma outra ação. Ressalto que o texto é conceitual e podemos aplicar em diversos outros segmentos. Como por exemplo o próprio semáforo inteligente.
Olá me chamo Franklin, comecei a usar o Zorin OS 09 a 3 dias.
Ainda estou tentando entender muitas coisas.
Li este artigo e não entendi muito bem o objetivo dele, seria que toda vez ao selecionar uma imagem ou um video ele detectar os objetos e animais?
Gostaria que se possível me recomendasse algumas etapas para melhor entender ou me adaptar ao linux. Me mudei para esse OS pela ideia de liberdade, mas ando com algumas problemas.
parabéns muito bom
esse artigo me lembra muito bem o Seriado Person of Interest
Muito bom!
Você teria algum how to para o reconhecimento de texto em placas de carros?
[5] Comentário enviado por murilo_ns em 06/08/2014 - 18:14h:
Muito bom!
Você teria algum how to para o reconhecimento de texto em placas de carros?
Ta ai uma boa ideia, o reconhecimento de placas de carro seriam um otimo projeto para o reconhecimento de placas frias, se bater com outros dados Marca/Modelo do veículo.
Oi Cabelo, muito obrigado por contribuir com mais um tutorial. Entretanto, eu não consegui encontrar o arquivo "cavalo_v6.mat" no diretório especificado. Está faltando alguma informação no artigo?
Abraços
Patrocínio

Destaques
Atenção a quem posta conteúdo de dicas, scripts e tal (1)
Artigos
Manutenção de sistemas Linux Debian e derivados com apt-get, apt, aptitude e dpkg
Melhorando o tempo de boot do Fedora e outras distribuições
Como instalar as extensões Dash To Dock e Hide Top Bar no Gnome 45/46
Dicas
Como Atualizar Fedora 39 para 40
Instalar Google Chrome no Debian e derivados
Consertando o erro do Sushi e Wayland no Opensuse Leap 15
Instalar a última versão do PostgreSQL no Lunix mantendo atualizado
Flathub na sua distribuição Linux e comandos básicos de gerenciamento
Tópicos
Placamae Asus H510M-E Aceita Linux? [RESOLVIDO] (8)
erro ao clonar repo github (3)
Clamav e suas atualizações (25)
Como adicionar módulo de saúde da bateria dos notebooks Acer ao kernel... (23)
Top 10 do mês
-

Xerxes
1° lugar - 72.748 pts -

Fábio Berbert de Paula
2° lugar - 58.091 pts -

Clodoaldo Santos
3° lugar - 45.607 pts -

Buckminster
4° lugar - 26.752 pts -

Sidnei Serra
5° lugar - 26.377 pts -

Daniel Lara Souza
6° lugar - 17.780 pts -

Mauricio Ferrari
7° lugar - 17.399 pts -

Alberto Federman Neto.
8° lugar - 17.379 pts -

Diego Mendes Rodrigues
9° lugar - 15.464 pts -

edps
10° lugar - 14.713 pts
Scripts
[Shell Script] Script para desinstalar pacotes desnecessários no OpenSuse
[Shell Script] Script para criar certificados de forma automatizada no OpenVpn
[Shell Script] Conversor de vídeo com opção de legenda
[C/C++] BRT - Bulk Renaming Tool
[Shell Script] Criação de Usuarios , Grupo e instalação do servidor de arquivos samba
A maior comunidade GNU/Linux da América Latina! Artigos, dicas, tutoriais, fórum, scripts e muito mais. Ideal para quem busca auto-ajuda.
Site hospedado por: